We shipped a new milestone of
Orion yesterday. For those who haven't heard about Orion yet, its goal is to build developer tooling that works in the browser, at web scale. The idea is to exploit internet design principles throughout, instead of trying to bring existing desktop IDE concepts to the browser.
There are two new features in this new milestone (
download) that I would like to highlight:
- the ability to install, as a user, editor actions supplied by third-party web sites, and
- a very early integration with Firebug.
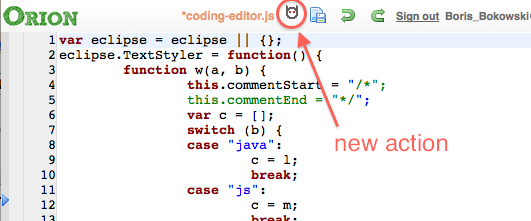
Editor Actions
In any decent editor, you'd want the ability to customize - adding new key bindings, new functionality, and changing its look. We have a first implementation that covers the first two of these, with an interesting twist: Editor actions can come from anywhere on the Internet!
Here is our favourite example, code formatting functionality for JavaScript files: Have a look at
http://jsbeautifier.org, which hosts a JavaScript formatter that is implemented in JavaScript, and has been developed independently of Orion. It was astonishingly easy to add a little bit of glue code around it to make it available as a command in the Orion editor. Thanks to
Einar Lielmanis, the author of this JavaScript code formatter, the resulting code is even hosted at jsbeautifier.org!
To make the command available in your local installation of Orion, you would go to
http://localhost:8080/view-registry.html, which is a special page showing your installed plugins. Enter
http://jsbeautifier.org/orion/jsbeautify.html in the text box and click on Install. The new plug-in should now be listed in the tree. Now navigate back to the Orion code editor, or hit reload on an existing Orion code editor in another tab, and enjoy the new action available in your editor's toolbar. You can read more about this in
Simon's blog - he implemented a lot of the frameworky stuff to make this possible.
This is a humble start of being able to pull functionality from all over the web into your development environment, which itself is web-based. Note that the server wasn't involved at all!
One of the next steps will be to add this extensibility to our navigator as well, and to expand what's possible from an editor action. Currently, editor actions see the selected text, the complete editor buffer, and the start and end of the current selection. They can change just the selection, or the complete buffer and the current selection. With just this minimal API, there is already a lot you can do - implement traditional editor actions, but also navigate within the editor buffer, change the contents of the entire buffer, or even contact a server for more heavy-duty processing.
If you have interesting ideas for what you could do with this, contact me (on
Twitter, the #eclipse-orion channel on
IRC, or the
Orion development mailing list) and I'll give you an account on our demo server at
http://orion.eclipse.org - we are slowly adding users there - so far it's by invitation only.
Firebug Integration
If you are doing web development,
Firebug is one of the indispensable tools these days. It does much more than the usual code debugger: yes, it lets you set breakpoints, single-step, and inspect variables visible from your stack, but it also supports monitoring HTTPS requests, inspecting the browser's DOM, looking at CSS styles, and more.
So instead of implementing some kind of debugger inside of Orion, it would be much better to integrate with existing debuggers that already exist. The question of course is, what does it mean to integrate? We have two main "integration points" in mind: being able to open the Orion editor on a file you see in Firebug, and synchronizing breakpoints between Firebug and Orion.
So far, we've worked on the first one only, as a start. It involved a little bit of code on the Orion side, and a little bit of code on the Firebug side. Thanks a lot to John J. Barton, the Firebug lead, for working with us on this! To try it out, you need to install a Firebug 1.7 alpha version as well as a Firebug extension called Dyne. The detailed instructions are
on the Firebug wiki. Once installed, you should be able to open
http://orion.eclipse.org/file/org.eclipse.orion.client.core/static/view-registry.html while Firebug is active. Open the script panel, you will see a new button "Edit". Clicking on this button opens the Orion code editor in a new browser tab.
Clearly, there is still ways to go before this flows nicely, but it's a great start. What I like in particular is that this is all based on an extra header Orion is sending, from which Firebug can construct the URL which contains the editor. This means that any web-editable resource could be edited in this way, just by adding custom headers - there is nothing Orion-specific that had to be put into the Firebug code base!
Looking Ahead
Both of these features illustrate the direction we want to take with Orion, and they align perfectly with our
development principles. I'll quote two of them here:
Reuse existing technologies - Don't re-invent the wheel if one already exists that we can integrate (through HTTP, or as open source that we consume), even if we could build a better wheel ourselves.
Low barrier of entry for adopters - We don't want to force people to have to re-write code just so that it fits into Orion, nor do we want them to have to re-write just so they can use one of our components.
Looking ahead, here is our list of ideas for additional integrations with existing web-based services:
- Paste selected text to pastebin.com.
- Create a new Gist from the current editor buffer.
- In the navigator, add an action to smush (remove unnecessary bytes from) an image.
- Multi-select a few files and click on an action to generate a CSS sprite.
- Upload the current editor buffer to codepad, and insert the result from running the code at the bottom of the editor buffer.
- Send files to the W3C validator.
- Look up a word in a thesaurus and display alternative names.
I'd love to hear your suggestions. What should we add to the list? What should we work on first? Would you be interested to work with us on a similar integration? You can contact me on
Twitter, the #eclipse-orion channel on
IRC, or the
Orion development mailing list.